- Published on
当 Flink 遇上向量数据库:构建 dofi Agent 的“终极记忆”
- Authors

- Name
- Charles Chen
在大数据开发者的世界里,传统的 CRUD 就像是在写日记,而构建一套 实时 AI 向量流水线,更像是给你的 Agent 装上了一个带有“语义联想”功能的大脑。
今天,我们不聊那些虚头巴脑的职场 PPT,直接把代码拆开了,看看如何用 Kafka + Flink + Ollama + Milvus 搭建一套年薪架构师级别的实时知识库。
1. 序幕:为什么数据不能直存 Milvus?
很多新手会问:“Agent 收到消息,直接写 Milvus 不就行了?搞什么 Kafka 和 Flink,脱裤子放屁吗?”
架构师视角: 如果你的 Agent 只是个玩具,确实可以直连。但如果你要处理的是海量风险控制日志(Risk Control Logs),或者是高频的实时交互,解耦和吞吐就是命门。
Kafka 是缓冲垫,确保你的 Telegram Bot 不会被瞬时的高并发冲垮。
Flink 是加工厂,它负责把“人话”变成“机器懂的向量”。
2. 核心链路:把“肯德基”变成 768 维的数字
我们的数据流转是这样的:
Telegram Bot -> Python Skill -> Kafka -> Flink (Async I/O) -> Ollama (Embedding) -> Milvus
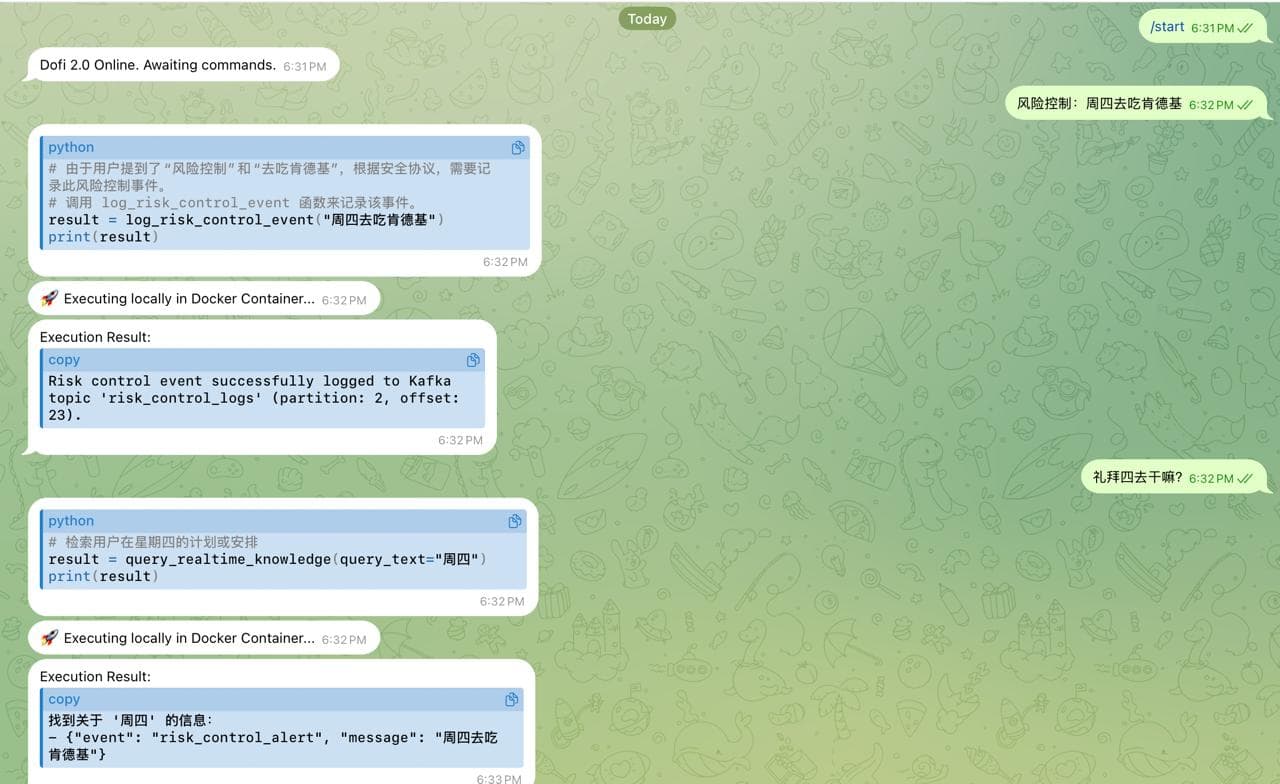
A. 消息的“第一推”:Kafka Producer
在 Python Skill 里,我们通过 KafkaProducer 把事件塞进队列。注意这里的 KAFKA_BROKER 配置:在 Docker 环境下,这就是一场关于 localhost 还是 kafka:29092 的哲学思辨。
避坑指南:如果你在容器里跑 Skill,千万别写
localhost,除非你想让 Agent 对着镜子自言自语。
import os
import json
import logging
from kafka import KafkaProducer
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("RiskControlSkill")
# Use environment variable to dynamically define the Kafka broker address,
# defaulting to the container internal address (kafka:29092) or host address (localhost:9092)
KAFKA_BROKER = os.getenv("KAFKA_BROKER", "kafka:29092")
TOPIC_NAME = "risk_control_logs"
def log_risk_control_event(event_message: str):
"""
Logs a risk control event to the Kafka topic.
Use this skill when the user sends messages mentioning risk control (风险控制) or related events like going to eat KFC (肯德基).
Tags: 风险控制, risk control, 风控
Args:
event_message: The message or details about the risk control event.
Returns:
str: A message indicating whether the event was successfully sent to Kafka.
"""
try:
producer = KafkaProducer(
bootstrap_servers=KAFKA_BROKER,
value_serializer=lambda v: json.dumps(v, ensure_ascii=False).encode('utf-8')
)
message_data = {
"event": "risk_control_alert",
"message": event_message
}
future = producer.send(TOPIC_NAME, value=message_data)
record_metadata = future.get(timeout=10)
producer.flush()
producer.close()
logger.info(f"Sent message to kafka topic {TOPIC_NAME}: {message_data}")
return f"Risk control event successfully logged to Kafka topic '{TOPIC_NAME}' (partition: {record_metadata.partition}, offset: {record_metadata.offset})."
except Exception as e:
logger.error(f"Failed to send risk control event to Kafka: {e}")
return f"Failed to log risk control event: {str(e)}"
B. 灵魂算子:Flink 异步向量化
这是整套架构中最有技术深度的地方。普通的 Flink Map 算子是同步的,如果你每来一条数据都去请求 Ollama 的 API,你的 Flink 任务会卡成 PPT。
我们使用了 AsyncDataStream.unorderedWait。
为什么异步? 因为 Embedding(向量化)是计算密集型,甚至是网络密集型的。
架构深度:通过
OllamaAsyncEmbeddingFunction,Flink 同时发出 100 个请求给本地的nomic-embed-text模型,最大化压榨 M4 Pro 那颗 16 核 GPU 的性能。这才是大数据工程师应有的尊严。
public class RealtimeRiskControlEmbeddingJob {
public static void main(String[] args) throws Exception {
// 1. 初始化环境并解析自适应参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool params = ParameterTool.fromArgs(args);
env.getConfig().setGlobalJobParameters(params); // 关键:全局共享参数
env.enableCheckpointing(5000);
// 2. 使用 MyParameter 工具类解析 Kafka 连接参数
MyParameter myParameter = new MyParameter(params);
// 3. Kafka Source (使用外部监听端口 9092)
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(myParameter.getKafkaUrl())
.setTopics(myParameter.getSourceTopic())
.setGroupId(myParameter.getKafkaGroupId())
.setStartingOffsets(OffsetsInitializer.latest()) // 确保能读到旧数据
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> kafkaStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 4. 异步向量化算子
DataStream<String> embeddedStream = AsyncDataStream.unorderedWait(
kafkaStream,
new OllamaAsyncEmbeddingFunction(),
30000L,
TimeUnit.MILLISECONDS,
100
);
// 5. 写入 Milvus Sink (必须确保 addSink 被正确调用)
embeddedStream.addSink(new VectorDatabaseSink()).name("Milvus-Sink");
// 6. 启动任务
env.execute("Dofi-Realtime-AI-Pipeline");
}
}
public class OllamaAsyncEmbeddingFunction extends RichAsyncFunction<String, String> {
private static final Logger LOG = LoggerFactory.getLogger(OllamaAsyncEmbeddingFunction.class);
private transient HttpClient client;
private String ollamaUrl;
@Override
public void open(Configuration parameters) {
ParameterTool params = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
MyParameter myParameter = new MyParameter(params);
String host = myParameter.getOllamaHost();
this.ollamaUrl = "http://" + host + ":11434/api/embeddings";
// 🌟 架构师视角:定制线程池
// 原生 HttpClient 默认使用无界缓存线程池,在 Flink 高吞吐异步 IO 时可能导致线程爆炸
// 这里显式指定一个有界或合理的线程池来控制并发资源消耗
this.client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(5))
.executor(Executors.newFixedThreadPool(20)) // 根据 TaskManager 的 CPU 核心数调优
.build();
}
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) {
try {
Map<String, String> body = new HashMap<>();
body.put("model", "nomic-embed-text");
body.put("prompt", input);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(ollamaUrl))
.timeout(Duration.ofSeconds(20))
// 1. 使用 Fastjson 序列化请求体
.POST(HttpRequest.BodyPublishers.ofString(JSON.toJSONString(body)))
.build();
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
.whenComplete((resp, throwable) -> {
if (throwable != null) {
LOG.error("请求 Ollama 失败: {}", input, throwable);
resultFuture.complete(Collections.emptyList());
return;
}
try {
if (resp.statusCode() == 200) {
// 2. 使用 Fastjson 解析响应
JSONObject node = JSON.parseObject(resp.body());
if (node.containsKey("embedding")) {
// 🌟 核心优化:拒绝手动拼接字符串,使用原生 JSON 对象构建
// 彻底杜绝 input 中包含奇葩转义字符导致 JSON 格式损坏的风险
JSONObject resultJson = new JSONObject();
resultJson.put("raw_log", input);
resultJson.put("vector", node.getJSONArray("embedding"));
// 直接输出序列化后的安全字符串
resultFuture.complete(Collections.singletonList(resultJson.toJSONString()));
} else {
LOG.warn("Ollama 返回数据格式异常: {}", resp.body());
resultFuture.complete(Collections.emptyList());
}
} else {
LOG.warn("Ollama 返回非 200 状态码: {}", resp.statusCode());
resultFuture.complete(Collections.emptyList());
}
} catch (Exception e) {
LOG.error("解析 Ollama 响应失败", e);
resultFuture.complete(Collections.emptyList());
}
});
} catch (Exception e) {
LOG.error("构建或发送 HTTP 请求时发生异常", e);
resultFuture.complete(Collections.emptyList());
}
}
@Override
public void timeout(String input, ResultFuture<String> resultFuture) throws Exception {
LOG.warn("❌ 数据处理超时 (超过了 Flink 设置的 Async Timeout) 丢弃数据: {}", input);
resultFuture.complete(Collections.emptyList());
}
}
public class VectorDatabaseSink extends RichSinkFunction<String> {
private transient MilvusClientV2 client;
@Override
public void open(Configuration parameters) {
ParameterTool params = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
MyParameter myParameter = new MyParameter(params);
String host = myParameter.getMilvusHost();
this.client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://" + host + ":19530").build());
// 🗑️ 删除了沉重的 ObjectMapper 初始化
}
@Override
public void invoke(String value, Context context) throws Exception {
// 1. 直接使用 Fastjson 解析原始字符串
JSONObject node = JSON.parseObject(value);
JSONObject row = new JSONObject();
row.put("raw_log", node.getString("raw_log"));
// 2. 提取向量数组
JSONArray vectorArray = node.getJSONArray("vector");
// 🌟 性能优化:直接指定 ArrayList 的初始容量
// 在 Flink 高频流处理中,避免 ArrayList 动态扩容带来的 CPU 和 GC 开销
List<Float> vector = new ArrayList<>(vectorArray.size());
for (int i = 0; i < vectorArray.size(); i++) {
vector.add(vectorArray.getFloat(i));
}
row.put("vector", vector);
InsertReq insertReq = InsertReq.builder()
.collectionName("dofi_realtime_knowledge")
.data(Collections.singletonList(row))
.build();
client.insert(insertReq);
System.out.println("🔥 成功持久化一条实时语义数据!");
}
@Override
public void close() {
if (client != null) {
try {
client.close(3000);
} catch (Exception e) {
System.err.println("关闭 Milvus 连接时发生异常: " + e.getMessage());
}
}
}
}
3. 存储与检索:Milvus 的“动态美”
在 Milvus 这一端,我们使用了 HNSW 索引。为什么不用简单的平铺搜索?因为我们要的是 毫秒级 的语义响应。
Schema 的考量
我们的 Schema 包含:
raw_log: 原始文本,方便人类阅读。vector: 768 维的向量(nomic 模型产出)。$meta: 这是一个动态 JSON 字段。在大数据架构中,动态字段是解决“Schema 频繁变更”的银弹。
搜索逻辑的进化
早期的 Skill 还在用 like "%周四%" 这种清朝时期的模糊查询。现在的我们,通过 Ollama 把用户的提问也向量化,然后去 Milvus 里做 余弦相似度(COSINE) 搜索。
幽默一刻: 当用户问:“我周四要去干嘛?”
普通查询:找遍数据库,发现没有“周四”两个字,宣告失败。
向量搜索:它知道“周四”和“礼拜四”、“Thursday”甚至“4月9日”在语义空间里是近邻,从而精准抓取记录。
import os
import logging
import requests
import json
from pymilvus import connections, Collection
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("MilvusKnowledgeSkill")
# 环境配置
MILVUS_HOST = os.getenv("MILVUS_HOST", "milvus-standalone")
MILVUS_PORT = os.getenv("MILVUS_PORT", "19530")
OLLAMA_URL = "http://host.docker.internal:11434/api/embeddings"
EMBED_MODEL = "nomic-embed-text" # 匹配你 schema 的 768 维度
def get_embedding(text: str):
"""调用本地 Ollama 获取向量数据"""
try:
response = requests.post(
OLLAMA_URL,
json={"model": EMBED_MODEL, "prompt": text},
timeout=5
)
return response.json().get("embedding")
except Exception as e:
logger.error(f"Ollama Embedding 失败: {e}")
return None
def query_realtime_knowledge(query_text: str) -> str:
"""
Searches the realtime knowledge base in Milvus for plans, schedules, or specific tasks.
Use this skill when the user asks about their plans for a certain day, like "周四要去干嘛" (what to do on Thursday) or "有什么计划" (any plans).
Tags: 计划, 安排, 干嘛, 周四, week, schedule, plan, plans, knowledge
Args:
query_text: The keyword or time period to search for (e.g., "周四").
Returns:
str: The retrieved knowledge records or a message indicating no results.
"""
try:
# 1. 连接 Milvus
connections.connect("default", host=MILVUS_HOST, port=MILVUS_PORT)
collection_name = "dofi_realtime_knowledge"
collection = Collection(collection_name)
collection.load()
# 2. 获取查询文本的向量 (768维)
query_vector = get_embedding(query_text)
if query_vector:
# 方案 A: 向量语义搜索 (推荐)
search_params = {"metric_type": "COSINE", "params": {"ef": 64}}
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=5,
output_fields=["raw_log", "$meta"] # 获取原始文本和元数据
)
hits = results[0]
else:
# 方案 B: 降级为标量查询 (如果 Ollama 不可用)
logger.warning("降级使用标量查询")
expr = f'raw_log like "%{query_text}%"'
hits = collection.query(expr=expr, output_fields=["raw_log", "$meta"], limit=5)
if not hits:
return f"未能查找到和 '{query_text}' 相关的记录。"
# 3. 结果格式化
formatted_results = []
for hit in hits:
# 根据查询方式不同,获取字段的方法略有区别
entity = hit.entity if hasattr(hit, 'entity') else hit
text_val = entity.get("raw_log", "无文本内容")
# 处理动态元数据 $meta (如果是 JSON)
meta_val = entity.get("$meta", {})
meta_info = f" [补充: {meta_val}]" if meta_val else ""
formatted_results.append(f"- {text_val}{meta_info}")
return f"找到关于 '{query_text}' 的信息:\n" + "\n".join(formatted_results)
except Exception as e:
logger.error(f"Milvus 操作失败: {e}")
return f"查询出错: {str(e)}"
finally:
# 生产环境下建议保持长连接,但在 Skill 脚本中显式释放资源较安全
pass
4. 结语:不只是代码,更是工程美学
一个合格的大数据工程师,不应该只满足于把数据搬来搬去。真正的乐趣在于,当你看到一个模糊的意图,经过 Kafka 的震荡、Flink 的洗礼、Ollama 的重塑,最后在 Milvus 的多维空间里精准定位时——那一刻,你不仅是在写代码,你是在构建一个活着的系统。
保持你的架构深度,剩下的,交给时间。
技术栈速览 (Stack Summary)
| 组件 | 版本 / 规格 | 关键点 |
| ------------- | ---------------- | ------------------------- |
| Kafka | 3.7.0 | 异步解耦,风控日志缓冲 |
| Flink | 1.18.1 | Async I/O 压榨 Embedding 吞吐 |
| Milvus | 2.4.x | HNSW 索引 + 动态 Schema |
| Embedding | nomic-embed-text | 768 维向量,本地化运行 |